Bidirectional Communication-Aware Offloading for Federated Prompt Learning at the Edge (to appear)
Abstract
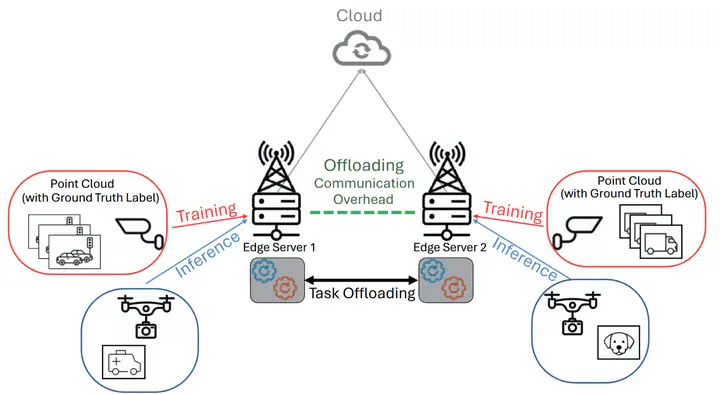
Federated learning (FL) has been increasingly applied to smart city applications to enable distributed model training while preserving data privacy. However, conventional weight-sharing FL still incurs high communication costs in bandwidth-constrained edge environments. Recently introduced Federated Prompt Learning (FPL) significantly reduces communication bandwidth usage to alleviate this issue. Nevertheless, performance degradation persists due to the coexistence of inference and training tasks and communication overhead, defined as delays arising from the transfer of tasks and associated data. Managing priorities between latency-sensitive inference and delay-tolerant training tasks is a critical challenge.
This paper models the offloading of inference and training tasks in FPL environments using queuing theory. Compared to the Task-Type Separation (TTS) method, we expand its control model and propose an improved offloading scheme that minimizes the mean sojourn time of training tasks while meeting delay requirements for inference tasks. This scheme allows for bidirectional offloading among multiple edge servers, reducing inference latency while maintaining training continuity. Analytical evaluations show that the proposed method satisfies inference delay requirements while maintaining acceptable training delays. This provides an autonomous, scalable task control mechanism for FPL-based edge systems.